

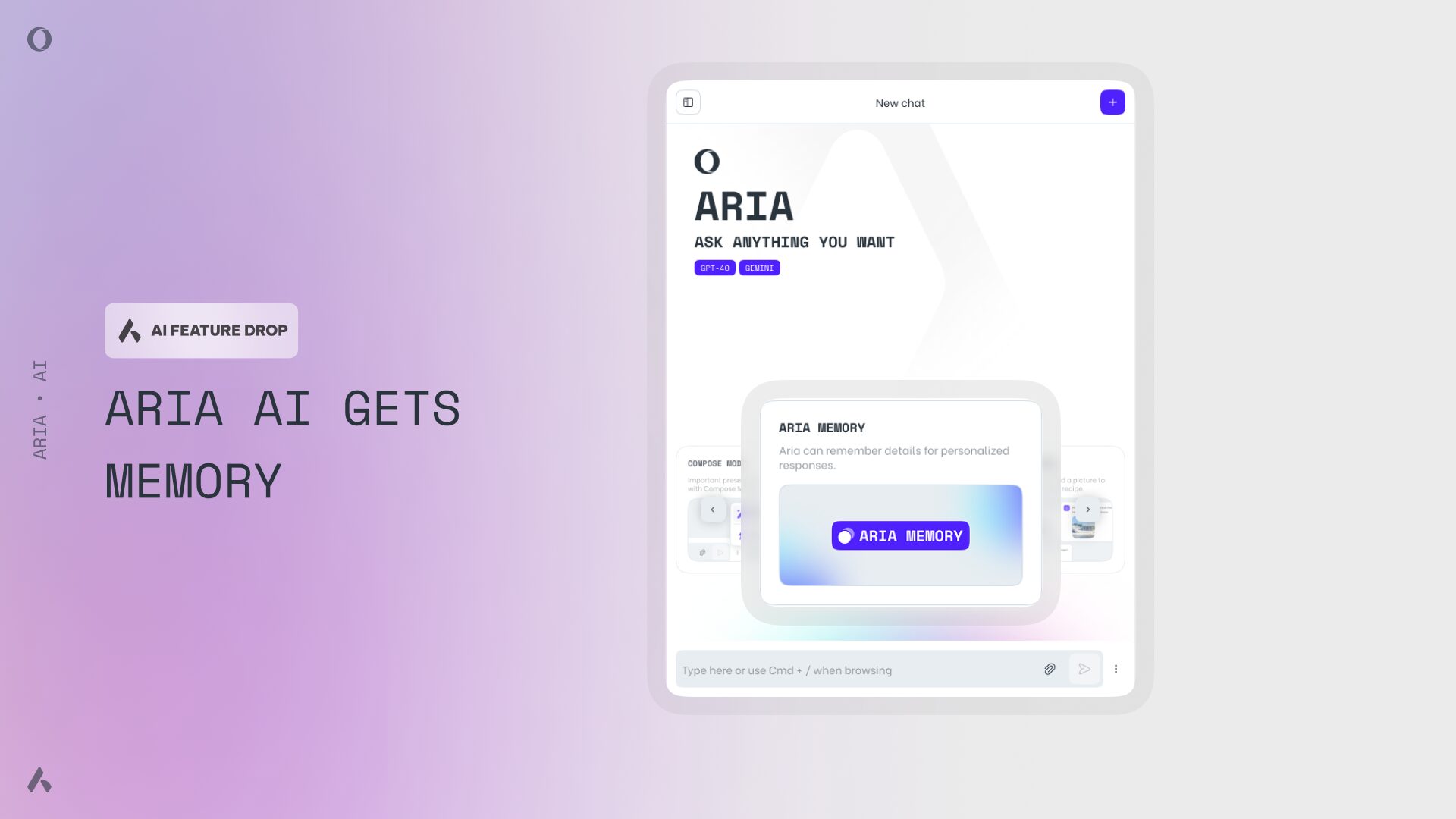
Hey all, Opera Air is back with another round of updates that allow you to further personalize our newest browser...










Opera's free VPN, Ad blocker, and Flow file sharing. Just a few of the must-have features built into Opera for faster, smoother and distraction-free browsing designed to improve your online experience.